
Robot Navigation Command Classification
Supervised machine learning study classifying wall-following robot commands from ultrasonic sensor readings
I built an offline supervised learning pipeline that classified pre-labeled robot wall-following commands from ultrasonic sensor snapshots. The useful part was treating it like an engineering validation problem: build a baseline, compare model families, keep preprocessing inside the training folds, and explain where the classifier still confused commands.
This was a machine learning class project using the UCI Wall-Following Robot Navigation Data Set. I worked with ultrasonic sensor readings from a SCITOS G5 robot and trained classifiers to predict pre-labeled wall-following commands.
I kept the project framed as offline supervised classification. That matters because the model is learning from labeled snapshots, not controlling a robot in the loop.
The main experiment used 5,456 samples with 24 ultrasonic sensor features and four command labels: Move-Forward, Slight-Right-Turn, Sharp-Right-Turn, and Slight-Left-Turn.
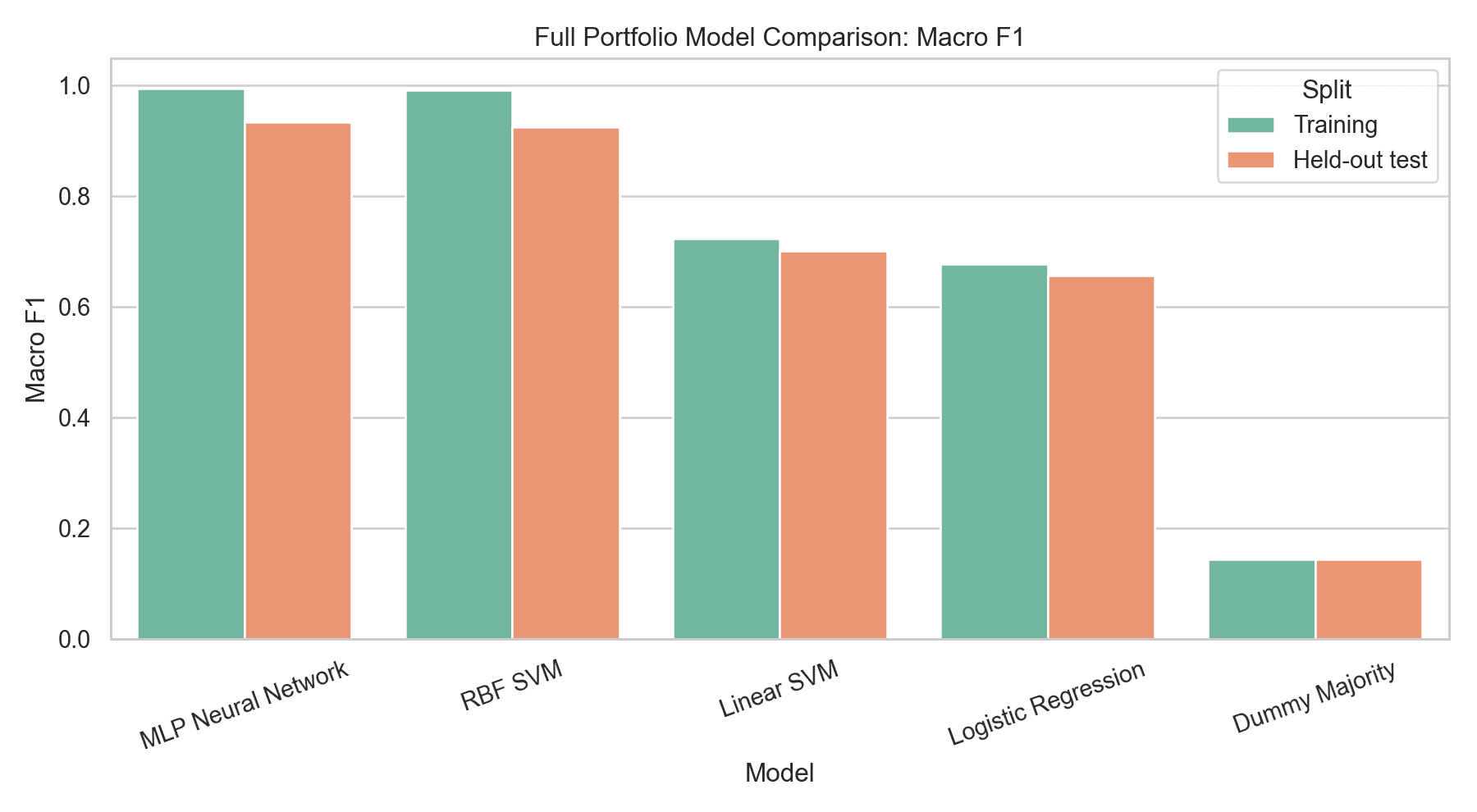
I compared a dummy majority baseline, logistic regression, linear SVM, RBF-kernel SVM, and an MLP neural network. Hyperparameters were selected with stratified 5-fold GridSearchCV using macro F1.
- Used scikit-learn Pipeline objects so scaling stayed inside training folds.
- Reported held-out test metrics instead of only training or cross-validation scores.
- Used macro F1 to keep minority command classes visible in the evaluation.
The MLP neural network was the strongest portfolio model, reaching 94.0% test accuracy and 0.934 macro F1 on the held-out test set. The best class-report model was the RBF SVM, with 92.9% test accuracy and 0.925 macro F1.
The model comparison was useful because the linear models lagged behind the nonlinear models, while the dummy baseline showed why accuracy alone was not enough for this dataset.
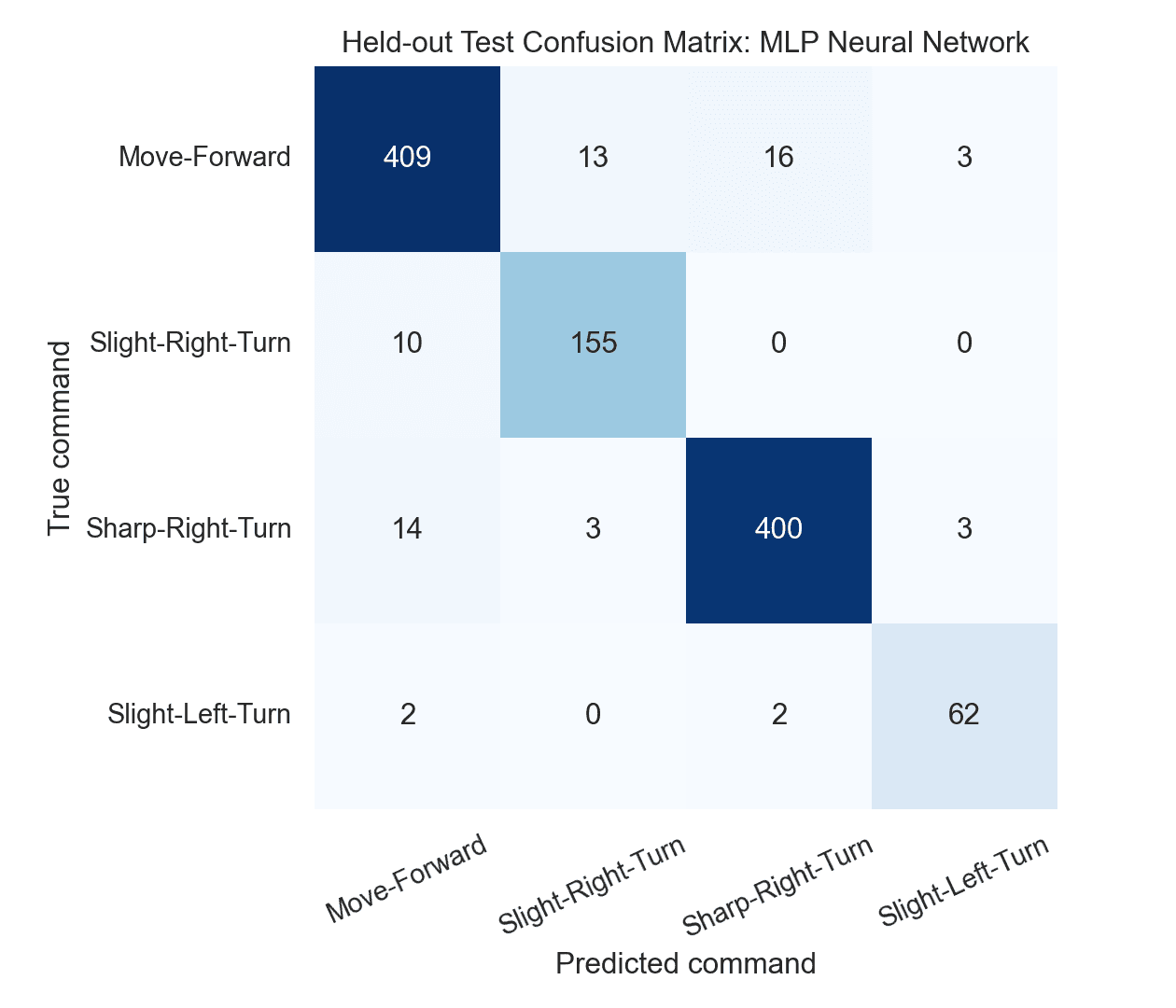
I used confusion matrices to look at the actual failure modes instead of stopping at one score. The largest off-diagonal error was Move-Forward predicted as Sharp-Right-Turn on 16 test samples.
That kind of mistake is important in a robotics context because adjacent command errors are not just abstract labels. They would need robot-in-the-loop testing before any classifier was trusted for control.
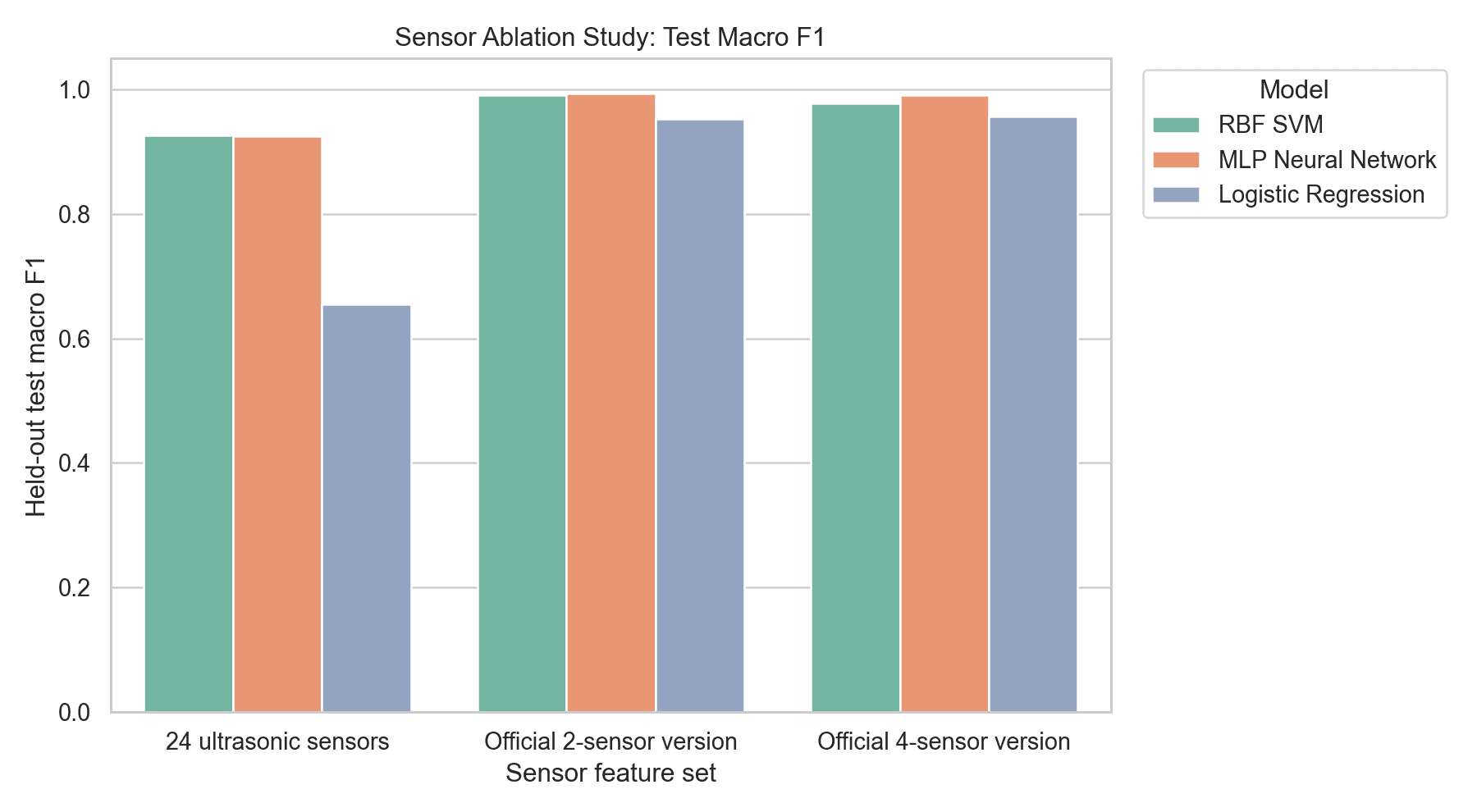
I also compared official reduced-sensor versions of the dataset. The reduced-sensor results did not support a simple claim that more raw sensor channels always improved classification.
That was a good reminder to keep model interpretation tied to the split, the dataset version, and the experimental setup instead of turning one result into a general rule.